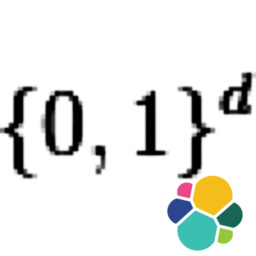|
(19th April 2023)
|
|
Youtuber Another Roof posed an interesting question on his video "The Surprising Maths of Britain's Oldest* Game Show". The challenge was stated in the video's description: "I want to see a list of the percentage of solvable games for ALL options of large numbers. Like I did for the 15 options of the form {n, n+25, n+50, n+75}, but for all of them. The options for large numbers should be four distinct numbers in the range from 11 to 100. As I said there are 2555190 such options so this will require a clever bit of code, but I think it’s possible!". His reference Python implementation would have taken 1055 days (25000 hours) of CPU time (when all four large numbers are used in the game), but with CUDA and a RTX 4080 card it could be solved in just 0.8 hours, or 31000x faster!
|
|
|
(2nd April 2023)
|
|
Bananagrams is a real-time word game in which participants race to build their own crosswords. It requires comprehensive vocabulary, fast thinking and good decision making. Some times situations arise which require an either-or decision: do I scrap my partial solution and do a fresh start or not? Or you may be left with one unusable extra letter, which you can put back into the pile and pick up three random new ones. This first article of the topic describes a two-phase artificial neural network which detects and identifies the tiles from an image. The second article will describe how to generate a valid crossword from given letters.
|
|
|
(10th November 2022)
|
|
Stable Diffusion is an image generation network, which was released to the public in 2022. It is based on a diffusion process, in which the model gets a noisy image as an input and it tries to generate a noise-free image as an output. This process can be guided by describing the target image in plain English (aka txt2img), and optionally even giving it a target image (aka. img2img). This article doesn't describe how the model works and how to run it yourself, instead this is more of a tutorial on how various parameters affect the resulting image. Non-technical people can use these image generating AIs via webpages such as Artistic.wtf (my and my friend's project), Craiyon.com, Midjourney.com and others.
|
|
|
(19th July 2022)
|
|
Some people enjoy solving puzzles in the old fashioned way, but engineers would like to automate tedious tasks like that. This is a well-suited task for supervised learning, but naturally it requires training data. Gathering it from real-life puzzles would be time-consuming as well, so I opted for generating it instead. This gives a lot of control on the data, but the resulting system might not even work with real-life inputs. There are also several different styles of puzzles, but in this project each "base-piece" is a rectangle of identical size. An example 3 × 3 puzzle is shown in the thumbnail.
|
|
|
(3rd February 2022)
|
|
Humans are naturally capable of separating an object from the background of an image, or speech from music on an audio clip. Photo editing is an easy task, but personally I don't know how to remove music from the background. A first approach would be to use band-pass filters, but it wouldn't result in a satisfactory end result since there is so much overlap between the frequencies. This article descripbes a supervised learning approach on solving this problem.
|
|
|
(15th January 2022)
|
|
This article describes a neural network which automatically projects a large collection of video frames (or images) into 2D coordinates, based on their content and similarity. It can be used to find content such as explosions from Arnold's movies, or car scenes from Bonds. It was originally developed to organize over 6 hours of GoPro footage from Åre bike trip from the summer of 2020, and create a high-res poster which shows the beautiful and varying landscape (Figure 9).
|
|
|
(15th December 2021)
|
|
The Finnish Inverse Problems Society (FIPS) organized the Helsinki Deblur Challenge 2021 during the summer and fall of 2021. The challenge is to "deblur" (deconvolve) images of a known amount of blur, and run the resulting image through and OCR algorithm. Deblur-results are scored based on how well the pytesseract OCR algorithm is able to read the text. They also kindly provided unblurred versions of the pictures, so we can train neural networks using any supervised learning methods at hand. The network described in this article isn't officially registered to the contest, but since the evaluation dataset is also public we can run the statistics ourselves. Hyperparameter tuning got a lot more difficult once it started taking 12 - 24 hours to train the model. I might re-visit this project later, but here its status described as of December 2021. Had the current best network been submitted to the challenge, it would have ranked 7th out of the 10 (nine plus this one) participants. There is already a long list of known possible improvements at the end of this article, so stay tuned for future articles.
|
|
|
(13th June 2021)
|
|
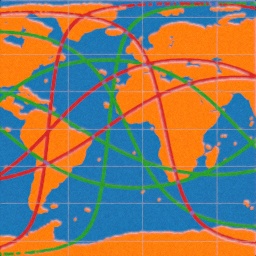
Since hearing the news of a faling Chinese rocket booster Long March 5B and being reminded that Earth's surface is about 70% ocean, I got interested on how the orbital parameters affect the odds of crashing to ocean vs. ground. I was nearly finished with the project when I realized that Earth is rotating under the satellite, thus invalidating all the results! This doesn't take orbits' eccentricity into account either, but I've heard that the athmospheric drag has a dendency of reducing it to zero as the orbit falls. Anyway, I found the various "straight" paths around the globe interesting and decided to publish these results anyway. In conclusion there are paths which spend only 9 % on top of land (including lakes) and 91% on top of ocean or up-to 57% on top of land and 43% on top of ocean.
|
|
|
(13th June 2021)
|
|
Youtube has a quite good search functionality based on video titles, descriptions and maybe even subtitles but it doesn't go into actual video contents and provide accurate timestamps for users' searches. An youtuber "Agadmator" has a very popular channel (1.1 million subscribers, 454 million video views at the time of writing) which showcases major chess games from past and recent tournaments and online games. Here a search engine is introduced which analyzes the videos, recognizes chess pieces and builds a database of all of the positions on the board ready to be searched. It keeps track of the exact timestamps of the videos in which the queried position occurs so it is able to provide direct links to relevant videos.
|
|
|
(20th November 2016)
|
|
Many businesses generate rich datasets from which valuable insights can be discovered. A basic starting point is to analyze separate events such as item sales, tourist attraction visits or movies seen. From these a time series (total sales / item / day, total visits / tourist spot / week) or basic metrics (histogram of movie ratings) can be aggregated. Things get a lot more interesting when individual data points can be linked together by a common id, such as items being bought in the same basket or by the same house hold (identified by a loyalty card), the spots visited by a tourist group through out their journey or movie ratings given by a specific user. This richer data can be used to build recommendation engines, identify substitute products or services and do clustering analysis. This article describes a schema for Elasticsearch which supports efficient filtering and aggregations, and is automatically compatible with new data values.
|
|
|
(10th October 2016)
|
|
When implementing real-time APIs most of the time server load can greatly be reduced by caching frequently accessed and rarely modified data, or re-usable calculation results. Luckily Python has several features which make it easy to add new constructs and wrappers to the language, for example thanks to *args, **kwargs function arguments, first-class functions, decorators and so fort. Thus it doesn't take too much effort to implement a @cached decorator with business-specific logic on cache invalidation. Redis is the perfect fit for the job thanks to its high performance, binary-friendly key-value store with TTL and different data eviction policies and support for other data structures which make it trivial to store additional key metrics there.
|
|
|
(23rd December 2015)
|
|
Traditionally data scientists installed software packages directly to their machines, wrote code, trained models, saved results to local files and applied models to new data in batch processing style. New data-driven products require rapid development of new models, scalable training and easy integration to other aspects of the business. Here I am proposing one (perhaps already well-known) cloud-ready architecture to meet these requirements.
|
|
|
(21st October 2015)
|
|
I encountered an interesting question at Stack Overflow about fuzzy searching of hashes on Elasticsearch and decided to give it a go. It has native support for fuzzy text searches but due to performance reasons it only supports an edit distance up-to 2. In this context the maximum allowed distance was eight so an alternative solution was needed. A solution was found from locality-sensitive hashing.
|
|