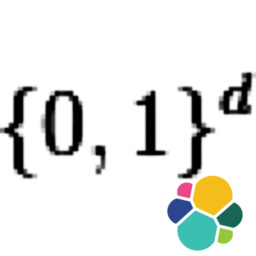|
(2nd April 2018)
|
|
Software projects are typically "tracked" on a version control system (VCS). Each "version" of the code is called a "commit", which does not only store file contents, but also plenty of metadata. This creates a very rich set of data, and in the age of open source there are thousands of projects to study. A few examples are Git of Theseus and Gitential, but by focusing on "git blame" (see who has committed each line on each file) I hope to bring something new to the table. In short I have analyzed how source code gets replaced by newer code, tracking the topics of who, when and why, and how old the code was.
|
|
|
(7th May 2017)
|
|
The NYC Taxi dataset has been used on quite many benchmarks (for example by Mark Litwintschik), perhaps because it has a quite rich set of columns but their meaning is mostly trivial to understand. I developed a Clojure project which generates Elasticsearch and SQL queries with three different templates for filters and four different templates of aggregations. This should give a decent indication of these databases performance under a typical workload, although this test did not run queries concurrently and it does not mix different query types when the benchmark is running. However benchmarks are always tricky to design and execute properly so I'm sure there is room for improvements. In this project the tested database engines were Elasticsearch 5.2.2 (with Oracle JVM 1.8.0_121) and MS SQL Server 2014.
|
|
|
(19th March 2017)
|
|
The NYC taxicab dataset has seen lots of love from many data scientists such as Todd W. Scheider and Mark Litwintschik. I decided to give it a go while learning Clojure, as I suspected that it might be a good language for ETL jobs. This article describes how I loaded the dataset, normalized its conventions and columns, converted from CSV to JSON and stored them to Elasticsearch.
|
|
|
(20th November 2016)
|
|
Many businesses generate rich datasets from which valuable insights can be discovered. A basic starting point is to analyze separate events such as item sales, tourist attraction visits or movies seen. From these a time series (total sales / item / day, total visits / tourist spot / week) or basic metrics (histogram of movie ratings) can be aggregated. Things get a lot more interesting when individual data points can be linked together by a common id, such as items being bought in the same basket or by the same house hold (identified by a loyalty card), the spots visited by a tourist group through out their journey or movie ratings given by a specific user. This richer data can be used to build recommendation engines, identify substitute products or services and do clustering analysis. This article describes a schema for Elasticsearch which supports efficient filtering and aggregations, and is automatically compatible with new data values.
|
|
|
(21st October 2015)
|
|
I encountered an interesting question at Stack Overflow about fuzzy searching of hashes on Elasticsearch and decided to give it a go. It has native support for fuzzy text searches but due to performance reasons it only supports an edit distance up-to 2. In this context the maximum allowed distance was eight so an alternative solution was needed. A solution was found from locality-sensitive hashing.
|
|
|
(26th April 2014)
|
|
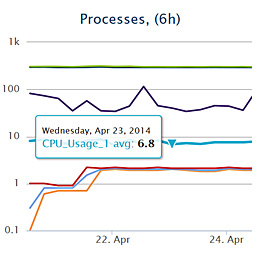
There already exists many server monitoring and logging systems, but I was interested to develop and deploy my own. It was also a good chance to learn about ElasticSearch's aggregation queries (new in v1.0.0). Originally ElasticSearch was designed to provide scalable document based storage and efficient search, but now it is gaining more capabilities. The project consists of a cron job which pushes new metrics to ElasticSearch, a RESTful JSON API to query statistics on recorded numbers and plot the results in a browser (based on HighCharts).
|
|