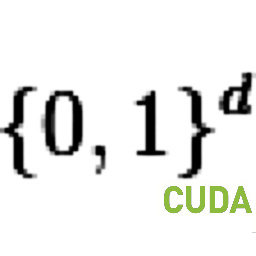|
(7th May 2017)
|
|
The NYC Taxi dataset has been used on quite many benchmarks (for example by Mark Litwintschik), perhaps because it has a quite rich set of columns but their meaning is mostly trivial to understand. I developed a Clojure project which generates Elasticsearch and SQL queries with three different templates for filters and four different templates of aggregations. This should give a decent indication of these databases performance under a typical workload, although this test did not run queries concurrently and it does not mix different query types when the benchmark is running. However benchmarks are always tricky to design and execute properly so I'm sure there is room for improvements. In this project the tested database engines were Elasticsearch 5.2.2 (with Oracle JVM 1.8.0_121) and MS SQL Server 2014.
|
|
|
(19th March 2017)
|
|
The NYC taxicab dataset has seen lots of love from many data scientists such as Todd W. Scheider and Mark Litwintschik. I decided to give it a go while learning Clojure, as I suspected that it might be a good language for ETL jobs. This article describes how I loaded the dataset, normalized its conventions and columns, converted from CSV to JSON and stored them to Elasticsearch.
|
|
|
(25th January 2017)
|
|
Mustache is a well-known template system with implementations in most popular languages. At its core it is logicless same templates can be directly used on other projects. For example I am planning to port this blgo engine from PHP to Clojure but I only need to replace LaTeX parsing and HTML generation parts, I should be able to use existing Mustache templates without any modifications. To learn Clojure programming I decided not to use the recommended library but instead implement my own.
|
|
|
(17th August 2016)
|
|
This is nothing that spectacular (as if anything on my blog is), but I still wanted to describe the outline of the project of porting the hyphenation algorithm from PHP to Clojure. The implementation is only about 80 lines of code + comments + 20 lines of unit tests. For comparison the original PHP abomination is about is about 160 LoCs, although it is a bit bloated by implementing the patterns search via a trie data structure instead of using the strpos function.
|
|
|
(7th August 2016)
|
|
After finishing a paid project, ideally a formal looking invoice would be sent to the client. I know there are many commercial products available, but I couldn't find a good open source alternative especially with the standard Finnish formatting. I was happy to find jheusala/finnish-invoice-template from GitHub which had all of the tricky LaTeX stuff done.
|
|
|
(16th April 2016)
|
|
Often I find myself having a SSH connection to a remote server, and I'd like to retrieve some files to my own machine. Common methods for this include Windows/Samba share, SSHFS and upload to cloud (which isn't trivial to do via plain cURL). Here an easy-to-use alternative is described: a single line command to load and run a docker image which contains a pre-configured Nginx instance. Then files can be accessed via plain HTTP at the user-assigned port (assuming firewall isn't blocking it).
|
|
|
(23rd December 2015)
|
|
Traditionally data scientists installed software packages directly to their machines, wrote code, trained models, saved results to local files and applied models to new data in batch processing style. New data-driven products require rapid development of new models, scalable training and easy integration to other aspects of the business. Here I am proposing one (perhaps already well-known) cloud-ready architecture to meet these requirements.
|
|
|
(2nd November 2015)
|
|
This is an alternative answer to the question I encountered at Stack Overflow about fuzzy searching of hashes on Elasticsearch. My original answer used locality-sensitive hashing. Superior speed and simple implementation were gained by using nVidia's CUDA via Thrust library.
|
|
|
(21st October 2015)
|
|
I encountered an interesting question at Stack Overflow about fuzzy searching of hashes on Elasticsearch and decided to give it a go. It has native support for fuzzy text searches but due to performance reasons it only supports an edit distance up-to 2. In this context the maximum allowed distance was eight so an alternative solution was needed. A solution was found from locality-sensitive hashing.
|
|
|
(25th April 2015)
|
|
Nowadays encryption is standard practice on web when data is in transition, and there are even a few services which offer client-side encryption and thus are truly end-to-end. Nevertheless for some reason they all require you to create and account by providing your email and password, although this is not strictly necessary for storing and sharing data. In this system the document id, encryption key and HMAC key are generated ad-hoc on the client and only minimal necessary information is revealed to the server. A live demo should be available at noknowledgenotes.nikonyrh.org.
|
|
|
(10th April 2015)
|
|
Out of interest on nature observation, computer vision, image processing and so forth I developed an automated system to capture one photo / minute and store it on a disk. The project also has Bash and PHP scripts coordinating external tools such as montage for image stitching and mencoder for video generation. PHP also provides an HTTP API for image generation and file size statistics.
|
|
|
(10th July 2013)
|
|
A good presentation about hyphenation in HTML documents can be seen here, but it is client side (JavaScript) oriented. Basically you shouldn't use justified text unless it is hyphenated, because long words will cause huge spaces between words to make the line stretch out the whole width of the element. I found a few PHP scripts such as phpHyphenator 1.5, but typically they weren't implemented as a single stand-alone PHP class. Since the underlying algorithm is fairly simple, I decided to write it from scratch.
|
|