

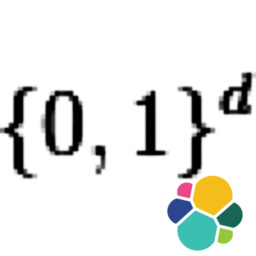
I encountered an interesting question at Stack Overflow about fuzzy searching of hashes on Elasticsearch and decided to give it a go. It has native support for fuzzy text searches but due to performance reasons it only supports an edit distance up-to 2. In this context the maximum allowed distance was eight so an alternative solution was needed. A solution was found from locality-sensitive hashing.
The situation is explained in the original question and the proposed solution is explained at my answer. In the stated problem millions of images were hashed into 64 bits, and given a hash we want to find "almost every" image with has a Hamming-distance of 8 or less. Not too many false matches should be returned either. The used hashing method is mentioned also in Wikipedia on locality-sensitive hashing article.
When the image is stored to ES, 1024 samples are taken and stored along with the image id and original hash. Each sample consist of 16 randomly (but consistently) selected bits which can be stored in Java's short data type. These values are stored to Lucene's search index but not stored along with the documents, this way index size is minimized on disk. Also _source and _all were disabled. Under this set-up 1 million documents in 4 shards with 1024 samples take about 6.7 GB of disk space. Without these optimizations the file size was 17.2 GB / index and queries on many indexes took about 67% longer.
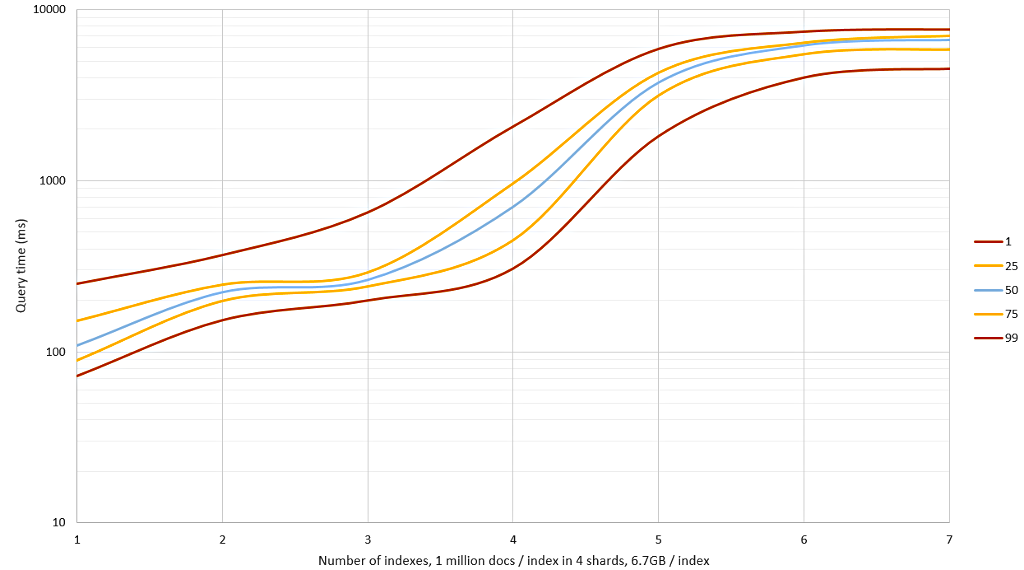
Query times' percentiles (1st, 25th, 50th, 75th and 99th) are shown in Figure 1 in log-scale. Times significantly increase once all data in the query context don't fit in memory (24 GB) and have to be read from two SSDs instead. On 3 million documents median response time was about 250 ms but for 6 million documents it grew to 6000 ms! Memory requirement could be lowered by taking fewer LSH-samples but it would result in poorer precision vs. recall tradeoff.
Related blog posts:
|
|
|
|
|
|
|
|
|
|
