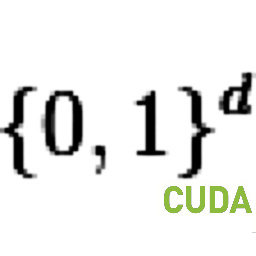|
(7th May 2017)
|
|
The NYC Taxi dataset has been used on quite many benchmarks (for example by Mark Litwintschik), perhaps because it has a quite rich set of columns but their meaning is mostly trivial to understand. I developed a Clojure project which generates Elasticsearch and SQL queries with three different templates for filters and four different templates of aggregations. This should give a decent indication of these databases performance under a typical workload, although this test did not run queries concurrently and it does not mix different query types when the benchmark is running. However benchmarks are always tricky to design and execute properly so I'm sure there is room for improvements. In this project the tested database engines were Elasticsearch 5.2.2 (with Oracle JVM 1.8.0_121) and MS SQL Server 2014.
|
|
|
(19th March 2017)
|
|
The NYC taxicab dataset has seen lots of love from many data scientists such as Todd W. Scheider and Mark Litwintschik. I decided to give it a go while learning Clojure, as I suspected that it might be a good language for ETL jobs. This article describes how I loaded the dataset, normalized its conventions and columns, converted from CSV to JSON and stored them to Elasticsearch.
|
|
|
(20th November 2016)
|
|
Many businesses generate rich datasets from which valuable insights can be discovered. A basic starting point is to analyze separate events such as item sales, tourist attraction visits or movies seen. From these a time series (total sales / item / day, total visits / tourist spot / week) or basic metrics (histogram of movie ratings) can be aggregated. Things get a lot more interesting when individual data points can be linked together by a common id, such as items being bought in the same basket or by the same house hold (identified by a loyalty card), the spots visited by a tourist group through out their journey or movie ratings given by a specific user. This richer data can be used to build recommendation engines, identify substitute products or services and do clustering analysis. This article describes a schema for Elasticsearch which supports efficient filtering and aggregations, and is automatically compatible with new data values.
|
|
|
(10th October 2016)
|
|
When implementing real-time APIs most of the time server load can greatly be reduced by caching frequently accessed and rarely modified data, or re-usable calculation results. Luckily Python has several features which make it easy to add new constructs and wrappers to the language, for example thanks to *args, **kwargs function arguments, first-class functions, decorators and so fort. Thus it doesn't take too much effort to implement a @cached decorator with business-specific logic on cache invalidation. Redis is the perfect fit for the job thanks to its high performance, binary-friendly key-value store with TTL and different data eviction policies and support for other data structures which make it trivial to store additional key metrics there.
|
|
|
(28th August 2016)
|
|
Traditionally computers were named and not easily replaced in the event it broke down. Server software was listening on a hard-coded port, and to link pieces together these machine names and service ports were hard-coded into other software's configuration files. Now in the era of cloud computing and service oriented architecture this is no longer an adequate solution, thus elastic scaling and service discovery are becoming the norm. One easy solution is to combine the powers of Docker, Consul and Registrator.
|
|
|
(2nd November 2015)
|
|
This is an alternative answer to the question I encountered at Stack Overflow about fuzzy searching of hashes on Elasticsearch. My original answer used locality-sensitive hashing. Superior speed and simple implementation were gained by using nVidia's CUDA via Thrust library.
|
|
|
(21st October 2015)
|
|
I encountered an interesting question at Stack Overflow about fuzzy searching of hashes on Elasticsearch and decided to give it a go. It has native support for fuzzy text searches but due to performance reasons it only supports an edit distance up-to 2. In this context the maximum allowed distance was eight so an alternative solution was needed. A solution was found from locality-sensitive hashing.
|
|
|
(26th April 2014)
|
|
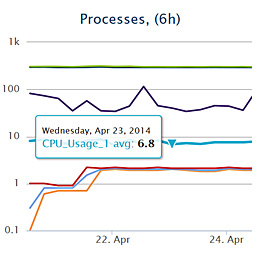
There already exists many server monitoring and logging systems, but I was interested to develop and deploy my own. It was also a good chance to learn about ElasticSearch's aggregation queries (new in v1.0.0). Originally ElasticSearch was designed to provide scalable document based storage and efficient search, but now it is gaining more capabilities. The project consists of a cron job which pushes new metrics to ElasticSearch, a RESTful JSON API to query statistics on recorded numbers and plot the results in a browser (based on HighCharts).
|
|
|
(1st December 2013)
|
|
Traditional databases such as MySQL are not designed to perform well in analytical queries, which requires access to possibly all of the rows on selected columns. This results in a full table scan and it cannot benefit from any indexes. Column-oriented engines try to circumvent this issue, but I went one step deeper and made the storage column value oriented, similar to an inverted index. This results in 2 — 10× speedup from optimized columnar solutions and 80× the speed of MySQL.
|
|