


An example game set is shown in Figure 1. There are a few different rule-sets, but in one of them each player is dealth N random tiles face down, and when everybody is ready, they are flipped over and it is just a race to construct a valid crossword which uses all the tiles.

The first step is to localize tiles from a given image. The training data was constructed by simply manually creating a black-and-white mask in GIMP, in which a pixel is white if it is near the center of a tile, or black if it is not. An example is shown in Figure 2.
Source videos have a resolution of 1920 × 1080, which are downscaled to 25% of the original size to a resolution of 480 × 270. Each frame's two halves are used as two separate samples, and the network is trained on rectangular images of resolution 270 × 270. The network could be trained with non-rectangular images as well, but data augmentation (especially image rotations) work better on rectangular ones.
Each sample is used to generate four versions of it, applying rotations by 0, 90, 180 and 270 degrees and also introducing gaussian blur with a random radius. Since there are 21 frames of training data, the shape of the Numpy array is 21 * 2 * 4 × 270 × 270 × 4 = 168 × 270 × 270 × 4. The last three dimensions are input image's red, green and blue values, and the fouth one is the intended mask. Examples are shown in Figure 3, where the last channel is combined with the input image's red channel.


The tile detection network uses only 2D convolutions and batch normalization, so in the fully integrated application it can be used directly on the 480 × 270 reolution frame. There are many hyperparameters to adjust (the number of stacked layers, number of kernels, amount of dropout, ...), but reasonable loss (binary cross entropy) and accuracy was obtained with the following structure. In the final application also real-time performance goal needs to be taken into account.
Here we can see that the resolution drops from 270 to 258 pixels, or by 12 pixels. This means that the decision on whether an output pixel belongs to a tile's center or not is done on a region of interest of ±6 pixels, or in other words 13 × 13 pixels. Taking the downscaling by 1:4 into account, this corresponds to ±24 or 49 × 49 pixels in the FullHD frame.
- Layer (type) Output Shape Param #
- =================================================================
- (None, 270, 270, 3) 0
- conv2d_6 (Conv2D) (None, 268, 268, 16) 448
- batch_normalization_5 (Batch (None, 268, 268, 16) 64
- conv2d_7 (Conv2D) (None, 266, 266, 10) 1450
- batch_normalization_6 (Batch (None, 266, 266, 10) 40
- conv2d_8 (Conv2D) (None, 264, 264, 10) 910
- batch_normalization_7 (Batch (None, 264, 264, 10) 40
- conv2d_9 (Conv2D) (None, 262, 262, 10) 910
- batch_normalization_8 (Batch (None, 262, 262, 10) 40
- conv2d_10 (Conv2D) (None, 260, 260, 10) 910
- batch_normalization_9 (Batch (None, 260, 260, 10) 40
- conv2d_11 (Conv2D) (None, 258, 258, 1) 91
- =================================================================
- Total params: 4,943
- Trainable params: 4,831
- Non-trainable params: 112
- _________________________________________________________________
Once the detection layer is trained, it can be used to extract individual tiles from videos. Image regions are cropped at ±64 pixels from the center, resulting in images of resolution 128 × 128. Examples of these are shown in Figure 4. Note that there are several aspects which make this classification task non-trivial:
- Camera's distance from the table isn't controlled, meaning that the letters may appear larger or smaller.
- The point of view isn't constrained to be top-down, meaning that there are distortion caused by perspective
- Tile's orientation is random, but still letters with similar structure such as A and V must be distinguished. And don't forget about Ä!
- Tiles are scattered on the table and not neatly separated, meaning that the network must learn to focus only on the tile on the middle of the image.
- Low light condition and camera motion cause noise and blur effects on images.

The identification network is trained using black and white images. The raw dataset consists of 4500 manually labeled images, with varying number of examples per class. The smallest one is G (49 images) and the most common is A (455 images). It should be noted that a Finnish version of the game was used, so letters like G, B and D are relatively rare and C is totally absent. Naturally image augmentation (random rotation, crop, noise, blur, ...) is used to extend the dataset. In the training and validation datasets each class had equal frequency, for example 5k or 20k samples per class. Examples are shown in Figure 5. Training is done on images rescaled to just 64 × 64 pixels, since this resulted in sufficient accuracy and is faster in the intended real-time application.

The network could be directly trained on "raw" unprocessed images, but better accuracy was obtained by co-training a pre-processing model simultaneously with the actual classification model. The task of the pre-processing model is to mask out irrelevant other letters near the image border, and optionally also increase the global contrast. The following network takes a sub-sampled 64 × 64 image and outputs either one or two predicted values, depending whether also the brightness is adjusted. The first output is the central letter's estimated radius (normalized to 0 - 1), and the second one is the amount of brightness to add. It has only a few thousand parameters, and seems to be working just fine.
- Layer (type) Output Shape Param #
- =================================================================
- (None, 64, 64, 1) 0
- conv2d_12 (Conv2D) (None, 60, 60, 16) 416
- max_pooling2d (MaxPooling2D) (None, 20, 20, 16) 0
- batch_normalization_10 (Batc (None, 20, 20, 16) 64
- conv2d_13 (Conv2D) (None, 18, 18, 6) 870
- max_pooling2d_1 (MaxPooling2 (None, 6, 6, 6) 0
- batch_normalization_11 (Batc (None, 6, 6, 6) 24
- conv2d_14 (Conv2D) (None, 4, 4, 6) 330
- batch_normalization_12 (Batc (None, 4, 4, 6) 24
- flatten (Flatten) (None, 96) 0
- dense (Dense) (None, 6) 582
- batch_normalization_13 (Batc (None, 6) 24
- dense_5 (Dense) (None, 2) 14
- =================================================================
- Total params: 2,348
- Trainable params: 2,280
- Non-trainable params: 68
- _________________________________________________________________
Using the pre-processing model is a bit non-trivial, it doesn't use the Sequential interface but instead the more generic Model one. It pre-calculates a "radius" tensor mr, with a distance value of zero in the middle and √2 in all corners, meaning that the used coordinate grid is from a range of -1 — 1 (from variables mx and my). The sigmoid activation is used in a manner which causes the added brightness to be zero in the image center, and one outside the estimated radius. Here some care needs to be taken, so that Tensorflow can apply proper broadcasting between these mis-matched tensors. And one must remember that the first zeroth dimension is NOT image's height, is the batch size!
If the output rx from the pre-processing model has more than one output, the second output is added to the image. Pixels are then clipped between values of zero and one, basically saturating the maximum brightness. Image is then re-normalized so that its minimum value is always zero. The maximum brightness could be smaller than one though. This source code is syntax-highlighted nicer on the PDF version.
- import tensorflow.keras.layers as l
- from tensorflow.keras.models import Model
- import tensorflow.keras.backend as K
- import numpy as np
- res = 64
- mx, my = np.meshgrid(*(np.linspace(-1, 1, res) for _ in range(2)))
- mr = tf.cast(((mx**2 + my**2)**0.5)[None,:,:,None], dtype=tf.float32)
- inp = l.Input(X_fit.shape[1:])
- rx = r_model(inp)
- # Add brightness outside the radius
- x = inp + K.sigmoid((mr - rx[:,0:1,None,None]) * 10)
- # Optionally increase the global brightness as well
- if rx.shape[1] > 1:
- x = x + rx[:,1:2,None,None]
- # Clip the brightness, re-scale the values so
- # that the darkest pixel has a value of zero
- x = K.clip(x, 0, 1)
- x_min = K.min(x, axis=(1,2))[:,:,None,None]
- x = (x - x_min) / (1 - x_min + K.epsilon())
- m_model = Model(inp, x)
The complete model is easily constructed with the Sequential interface, and it can incorporate the pre-processing model without any issues. There are quite many hyperparameters to choose from, but this resulted in a fairly good accuracy. The model has about 80k paramaters, starting with typical Conv2D, BatchNormalization, SpatialDropout2D and MaxPooling2D layers and finishing up with fully connected Dense layers.
It was a bit surprising that the pre-processing model worked out so well, even with totally random initialization and no explicit information on the correct radius. It just learned that especially when the camera was far away and the central letter covers just a small part of the image, it is important to mask out all extra letters so that they don't confuse the deeper layers. Estimated radii and pre-processed images are shown in Figure 6, sorted from smallest to largest. Bounding circles aren't 100% tight, but here a high precision isn't required.
- Layer (type) Output Shape Param #
- =================================================================
- (None, 64, 64, 1) 0
- model_1 (Functional) (None, 64, 64, 1) 2348
- conv2d_21 (Conv2D) (None, 62, 62, 48) 480
- max_pooling2d_7 (MaxPooling2 (None, 31, 31, 48) 0
- spatial_dropout2d_3 (Spatial (None, 31, 31, 48) 0
- batch_normalization_22 (Batc (None, 31, 31, 48) 192
- conv2d_22 (Conv2D) (None, 28, 28, 48) 36912
- max_pooling2d_8 (MaxPooling2 (None, 14, 14, 48) 0
- spatial_dropout2d_4 (Spatial (None, 14, 14, 48) 0
- batch_normalization_23 (Batc (None, 14, 14, 48) 192
- conv2d_23 (Conv2D) (None, 12, 12, 48) 20784
- max_pooling2d_9 (MaxPooling2 (None, 4, 4, 48) 0
- spatial_dropout2d_5 (Spatial (None, 4, 4, 48) 0
- batch_normalization_24 (Batc (None, 4, 4, 48) 192
- flatten_3 (Flatten) (None, 768) 0
- dense_6 (Dense) (None, 22) 16918
- batch_normalization_25 (Batc (None, 22) 88
- dense_7 (Dense) (None, 22) 506
- =================================================================
- Total params: 78,612
- Trainable params: 78,212
- Non-trainable params: 400
- _________________________________________________________________

Estimated radii and optimal brightnesses are shown in Figure 7. Note that unlike in Figure 6, in 7 images are sorted by the amount of added brigthness. This means that the letter K on top left has the least amount of extra brigthness (it being already on a very bright background, and a correctly estimated bounding circle), and the U on bottom right had the darkest background. The resulting images have very few extra artefacts, except the square tile's shadow in some cases.

Class accuracies and confusion matrices for fit and validation data are shown in figures 8 and 9. The confusion matrix has a white column for letters which were identified correctly 100% of the time.
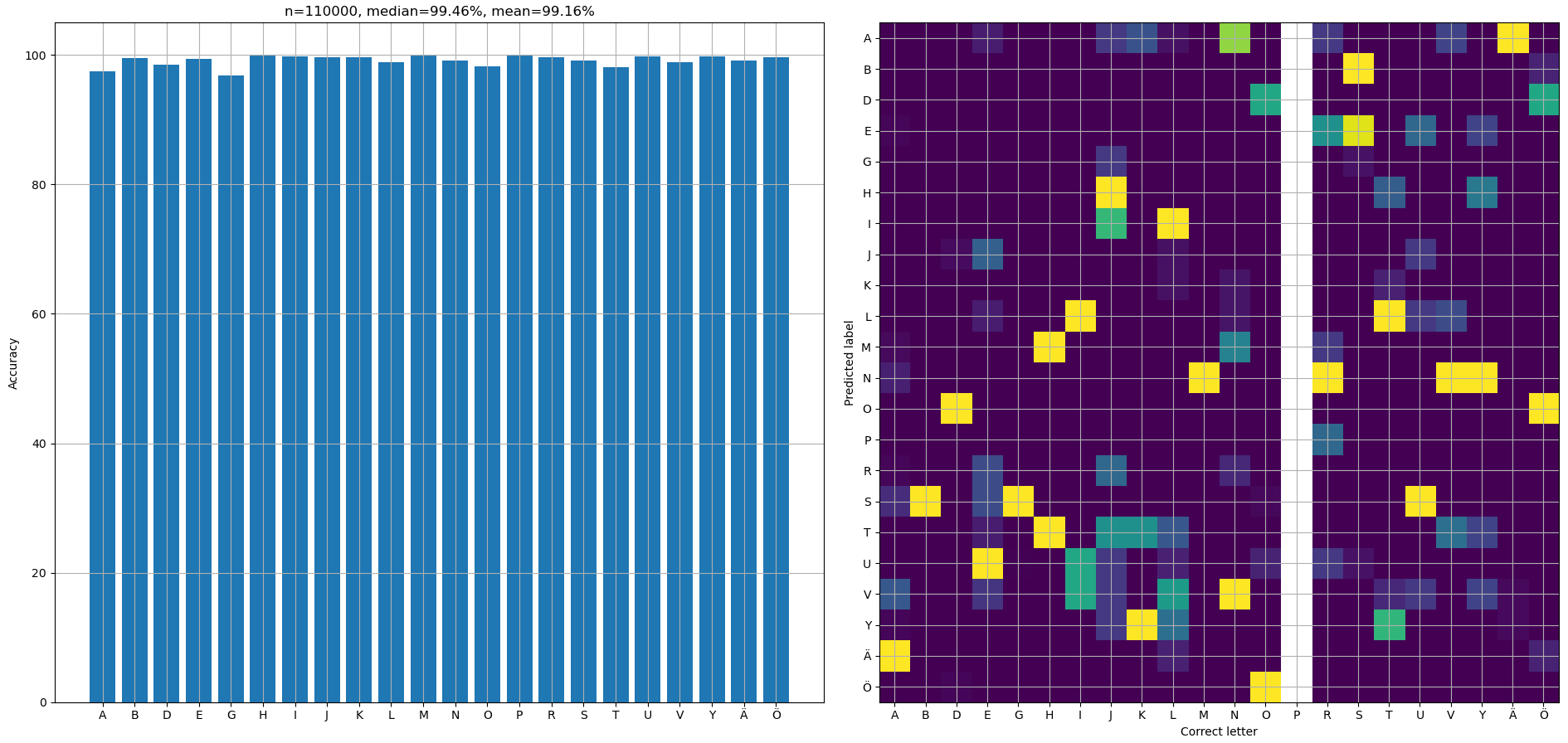
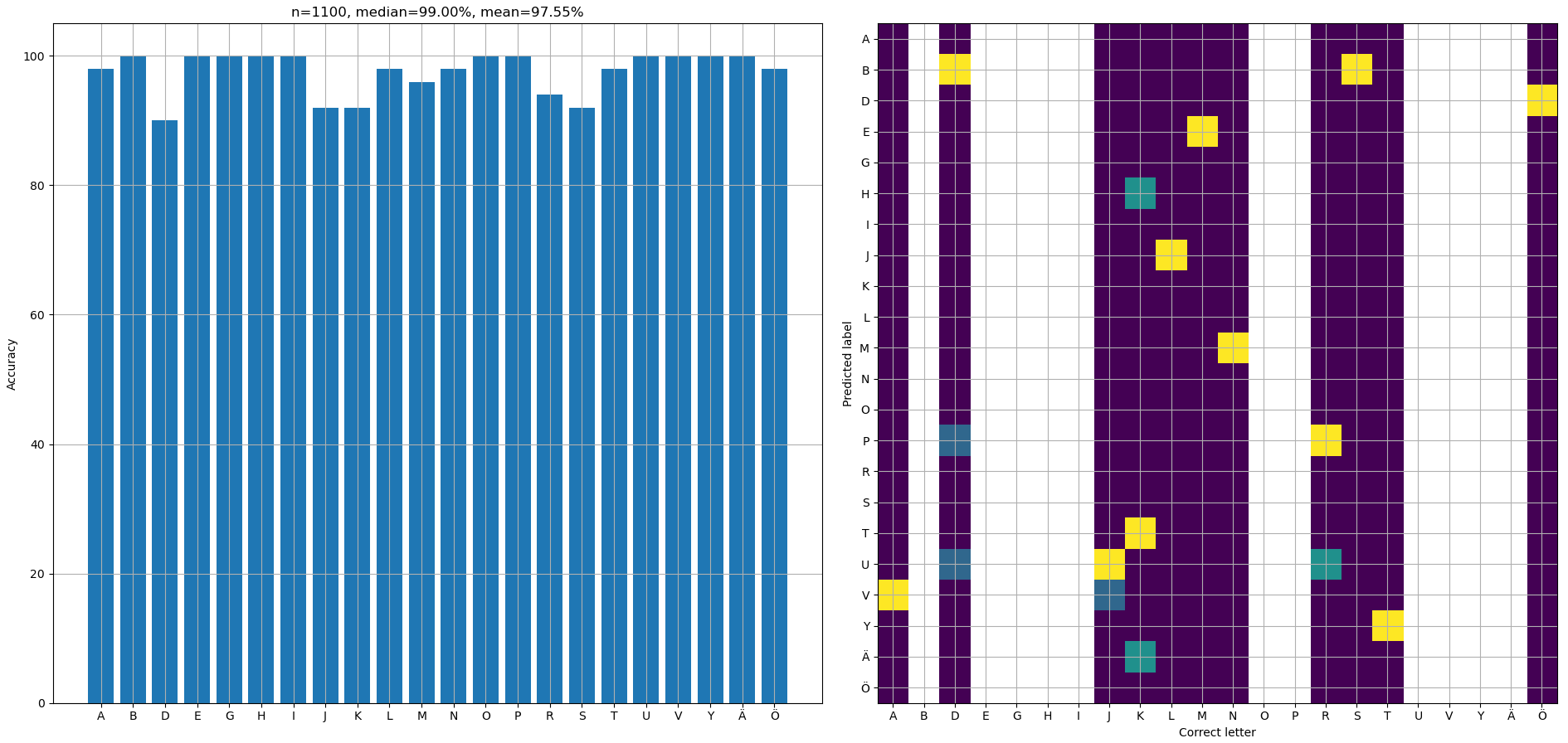
Average fit and validation accuracies were 99.2% and 97.6%, correspondingly. Removing the pre-processing model drops accuracies to 27.5% and 28.4% if the model isn't re-trained, since it hasn't learned to be tolerant of irrelevant letters around the central tile. But actually training the model without pre-processing got accuracies of 99.3% and 97.1%, meaning that it brings hardly any benefit afterall! Well, at least it produced some nice visualizations and such approach should be actually useful in some other problems. Shown results are from a model with pre-processing, and it had a dropout rate of 0.03. Validation loss is noticeably higher than training loss, but increasing the dropout rate didn't improve the validation accuracy at all.
Overall this project was kind of a success, but even the 97% — 99% accuracy isn't sufficient for the intended application. The reason is that if even a single false negative or positive tile detection occurs, letter frequencies will be wrong and the suggested solution is impossible.
But even if tile detection is perfect, the letter classification must be 100% accurate as well. But given that there are 20 - 30 letters to classify at once, 97% success rate means that there is only 40 — 54% probability getting all of them correct. Well if A gets mixed up with V and vice versa the letter counts still match, but a robust system cannot rely on such luck. Example results are shown in figures 10 and 11.


There are a few approaches to improve the situation. Naturally more training data is valuable, ideally having the tiles on varying backgrounds and light directions but labeling it is very tedious. Experiments with better data augmentation could be done, for example by introducing light gradients and other more complex distortions. Or the images could be completely artificial, if 3D rendering is applied. These results are from 5k samples per letter, but it could easily be scaled up to 50k. At the moment it is unknown how much this would help with overfitting.
Secondly, hyperparameters could be tuned further. But the network is intended to be used in a real-time application, so it cannot be overly heavy. Thus also ensemble methods seem like implausible solution.
Thirdly, a totally different network architectures should be tested, most importantly the famous YOLO. Unlike the two-step approach represented here, YOLO looks the image only once (hence the name) and determines optimal bounding boxes and object classes simultaneously! The current network could be used to generate the training data, especially since it can also predict the bounding circle.
Finally, since the application uses video feeds and not just one still image, we can apply voting and other statistical methods on a sequence of predictions. This would cause the final predictions to lag behind somewhat, but it doesn't hurt the demo too much as long as the FPS stays sufficiently high.
This article's part two will describe how to generate valid crosswords given letter frequencies, in just 15 milliseconds, by using Numba, NumPy, data-structures and algorithms. It is worth mentioning that the first working version of the code took 15 seconds (1000x slower) to do the same thing.
Related blog posts:
|
|
|
|
|
|
|
|
|
|
