


I developed a coin recognition system which can recognize eight different groups of coins. The used set is all five coins of Singapore, but a few categories cannot be distinguished from each other without knowledge of the coin's size in relation to others.
I had earlier done a coin recognition system, but it had only four categories (10 and 20 cent Singaporean coins on both sides). The used photos were deliberately corrupted by very heavy JPG compression, but I still felt the problem wasn't fully solved. It used Support Vector Machines as the final classifier, and reached about 99% accuracy levels.
For the second round of experiments, I arranged coins into a regular pattern on a sheet of paper and took 40 photos from different angles. An example photo can be seen in Figure 1. Coins were automatically extracted from these images, converted to grayscale, resized to 256 × 256 resolution and stored to a dedicated folder. Then 30 example coins of each category were hand-picked and put to labeled folders, which were used as training data for the supervised learning algorithm. At this stage I realized that 10 cent and 50 cent coins had identical pattern, and also 5 cent and 20 cent coins.
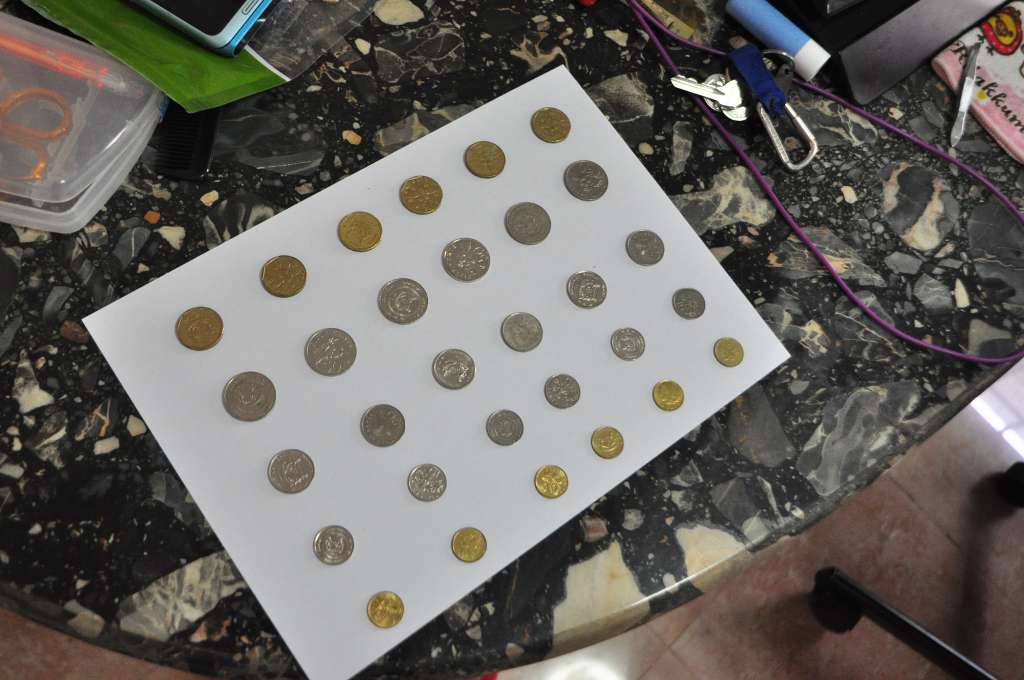
The feature extraction process is shown in Figure 2. It utilizes log-polar coordinates and the absolute value of Discrete Fourier Transform (DFT) to produce rotation and scale invariant descriptors. The current coin extraction method is a bit inaccurate in defining the coin boundaries, and thus the coin might not be centered properly in the cropped image. To make the system robust against such errors, each coin in the training set was displaced several times and these were treated as independent training examples.
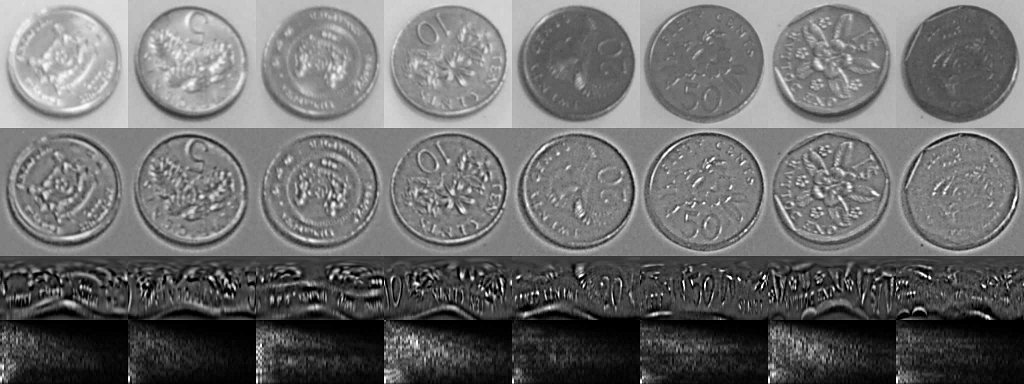
The used machine learning algorithm is Linear Discriminant Analysis, because it is easy to implement and doesn't have many tuning parameters. It also handles high-dimensional data with relative ease, and in this case the data had 64 × 64 dimensions! This is the result of first generating 128 × 64 log-polar image, for which the DFT was calculated. The absolute values of this transform have redundancy in the data, and thus a 64 × 64 window is sufficient. It is important to note that the used DFT was done in 1D, not 2D as sometimes is the case.
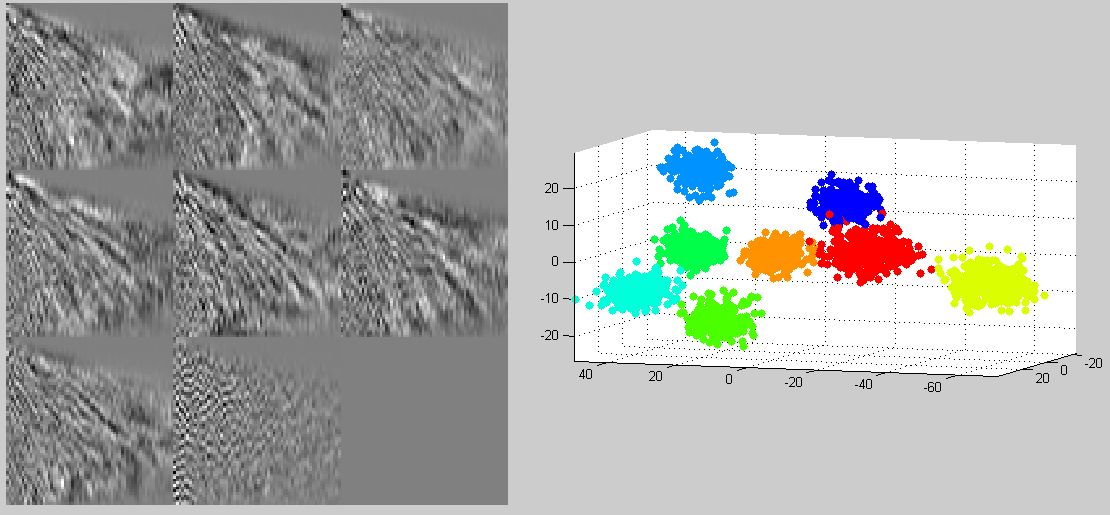
The Linear Discriminant Analysis was used to create 8 linear classifiers (one for each class), each of which could distinguish items of the corresponding class from all other classes. This already reduces the dumber of dimensions from 4096 to 8, but actually that set of base vectors has only 7 degrees of freedom. The final post-processing step was to perform Principal Component Analysis and drop the vector with smallest eigenvalue. This also helps with plotting the resulting point clouds, so that the within-class and between-class covariance can be visually observed. The resulting point clouds can be seen in Figure 3. The odd looking patterns on the left are the linearly discriminating base vectors.
Once the data points have been transformed with the combined linear transformation of LDA and PCA, the data mean and covariances are calculated. During the matching stage these are used to calculate the Mahalanobis distance from given point and each of the classes. Then metrics such as the distance from closest cluster, and the ratio of distances to 1st and 2nd closest clusters can be used to determine the most likely label, and also estimate the likelihood of the estimate being correct.

Examples of correctly identified coins can be seen in Figure 4. Some of the coins are difficult to recognize even for a person who is used to handle these coins, because the high-contrast details might be lost. The system could be improved my compensating for view point differences, which causes the coin to have an ellipse-like shape.
In future I might add more training data, labelled test data and ROC (Receiver Operating Characteristics) plots. Also in case some of the coins can be recognized, this gives us valuable information about the relative scale of the coins. This would enable us to distinguish between back sides of 10 and 50 cent coins, and solve other ambiguous situations by using belief propagation methods. I haven't use those in practice yet, but they don't seem to be too complicated to implement.
Related blog posts:
|
|
|
|
|
|
|
|
|
|
